
接口链接:
- api.horosama.com # 默认接口,对应的是赫萝的壁纸图片
- api.horosama.com/rand_phone.php # 赫萝的手机壁纸接口
使用Sakurairo主题的时候,主页背景等都可以选择用随机图片接口,但看了下说明文档里提供的接口,有的不维护了,有的不稳定速度慢,可以用的一些接口里的图自己也不太喜欢,于是萌发了自己搭建一个随机图片接口的想法。
经过万能的百度,参考了以下几个链接,最终成功搭建了出来~:
- 【vps】教你写一个自己的随机图API
- 超简单随机图片API制作教程
下面记录一下自己的搭建过程~首先当然是准备图包啦,这里我用了自己以前写的python自动抓取百度图片的脚本,代码如下:
#! 自己的python解析器地址
#-*-coding:utf-8-*-
import random
import re
import os
import time
import requests
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
class BaiduPicture:
def __init__(self):
self.url = 'https://image.baidu.com/search/acjson?{}'
def get_image(self, word, page, pn_end,index_start,path):
"""_summary_:获取图片链接并保存图片
Args:
word (str) : 图片关键词
page (int) : 起始页数
pn_end (int) : 终止页数
index_start (int) : 起始索引
path (str) : 保存路径
"""
word = word
image_url = []
for i in range(page, pn_end + 1):
params = {
'tn': 'resultjson_com',
'logid': '###',# 换成自己的logid
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'fr': '',
'word': word,
'queryWord': word,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'hd': '',
'latest': '',
'copyright': '',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'expermode': '',
'nojc': '',
'isAsync': '',
'pn': str(30 * i),
'rn': '30',
'gsm': '5a',
}
response = requests.get(url=self.url, headers={'User-Agent': random.choice(ua_list)}, params=params)
response.encoding = 'utf-8'
response = response.text
re_pat = '"thumbURL":"(.*?)"'
pattern = re.compile(re_pat, re.S)
result = pattern.findall(response)
if (len(result) > 0):
image_url.extend(result)
time.sleep(random.random()+1)
if len(image_url) > 0:
print('共{}个图片需要下载'.format(len(image_url)))
for index, image in enumerate(image_url):
file_name = word + "_" + str(index_start+index + 1) + '.jpg'
time.sleep(random.randint(1, 2))
self.save_image(image, file_name, word,path)
print('下载完成')
def save_image(self, url, file_name, word,path):
"""_summary_:保存图片
Args:
url (str) : 图片链接
file_name (str) : 图片名称
word (str) : 图片关键词
path (str) : 保存路径
"""
html = requests.get(url, headers={'User-Agent': random.choice(ua_list)}).content
path = os.path.join(path, word)
if not os.path.exists(path):
os.makedirs(path)
file_path = os.path.join(path, file_name)
with open(file_path, 'wb') as f:
f.write(html)
print('{}已保存'.format(file_name))
def run(self):
"""_summary_:主函数
"""
word = input('输入需要下载的图片关键词:')
pn = int(input('输入起始页数:'))
pn_end = int(input('输入终止页数:'))
index_start = int(input('输入起始索引:'))
path = input('输入保存路径:')
if not os.path.exists(path) or path == '':
path = os.getcwd()
self.get_image(word, pn, pn_end,index_start,path)
if __name__ == '__main__':
baidu = BaiduPicture()
baidu.run()
以赫萝为关键词,抓取了图片之后,分别放入到pc和phone两个文件夹里,对应横屏壁纸和手机端竖屏壁纸,这样图包就准备好啦。在自己的服务器的根目录下新建了一个api文件夹,然后把图片文件夹放到了/api/img目录下。用python又写了个小程序,自动根据文件名和目录,生成了如下内容的两个txt文件,分别对应pc和phone,都放到/api目录下:
http://www.horosama.com/api/img/pc/pc_1.jpg
http://www.horosama.com/api/img/pc/pc_2.jpg
http://www.horosama.com/api/img/pc/pc_3.jpg
....这个时候再在api目录下,新建两个php文件,文件内容如下,准备工作就做好啦:
<?php
$str = explode("\n", file_get_contents('XXXX'));//读取文件,把XXX换成自己的txt文件名
$rand_index = rand(0,count($str)-1);
$url = $str[$rand_index];
$url = str_re($url);
header("Location:".$url);
function str_re($str){
$str = str_replace(' ', "", $str);
$str = str_replace("\n", "", $str);
$str = str_replace("\t", "", $str);
$str = str_replace("\r", "", $str);
return $str;
}
?>最后,去云服务器上把域名api.horosama.com添加了到服务器IP的解析,再去云服务的宝塔界面里,进入网站选项,添加了一个新网站api.horosama.com,注意这里的根目录要填"/服务器根目录/api"。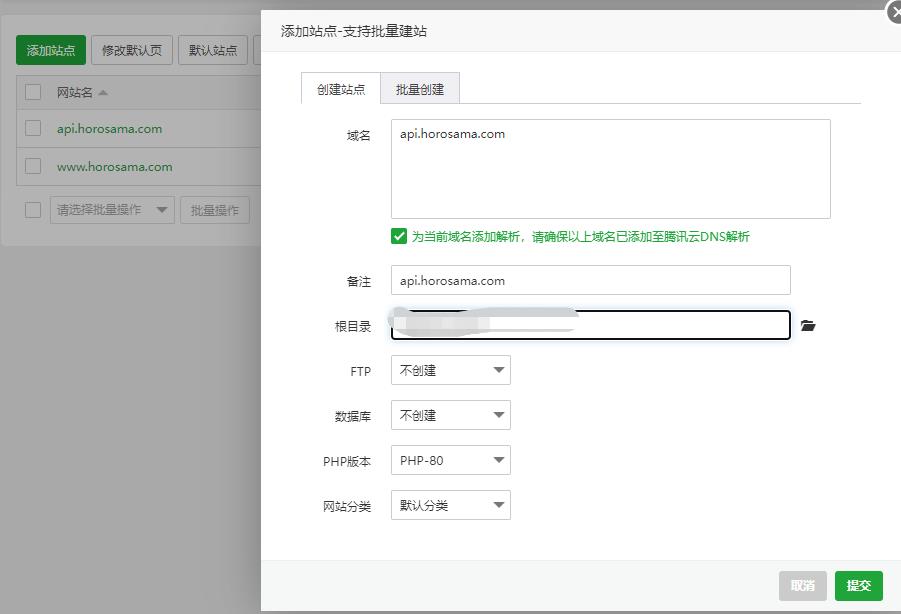
这个时候api.horosama.com就可以访问啦,但宝塔默认的访问页面是自动生成的index.php文件,所以去宝塔的网站控制台里,把默认文档这个选项里,换成刚才自己写的php文件,这个时候api.horosama.com就可以正常生成随机图了~~。
把自己网站的pc端和手机端的主页背景图片接口都换成自己的,大功告成!